DataWave
DataWave is an advanced tool developed in Python, designed to facilitate the training and customization of Natural Language Processing (NLP) models using unstructured text sources, that aims to provide users with an intuitive and effective way to analyze and visualize relationships between terms extracted from diverse text formats. The tool’s key feature is its ability to create dynamic graph force representations that showcase the interconnections between terms, allowing users to explore and manipulate these relationships through operations such as creating, deleting, renaming terms, and adjusting the weight of connections.
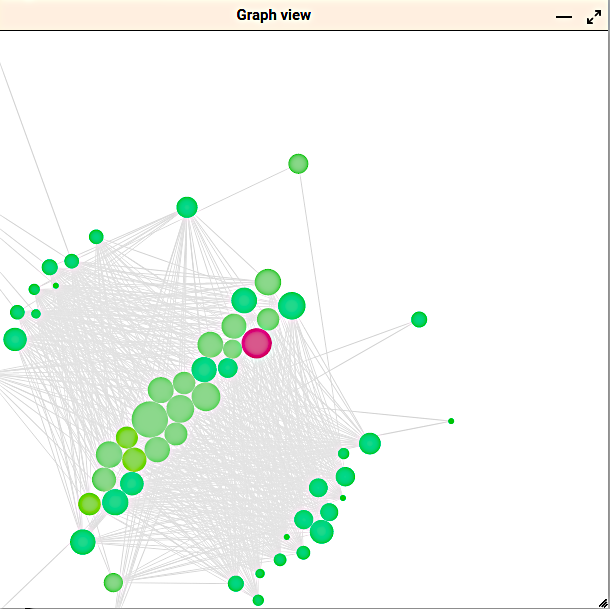
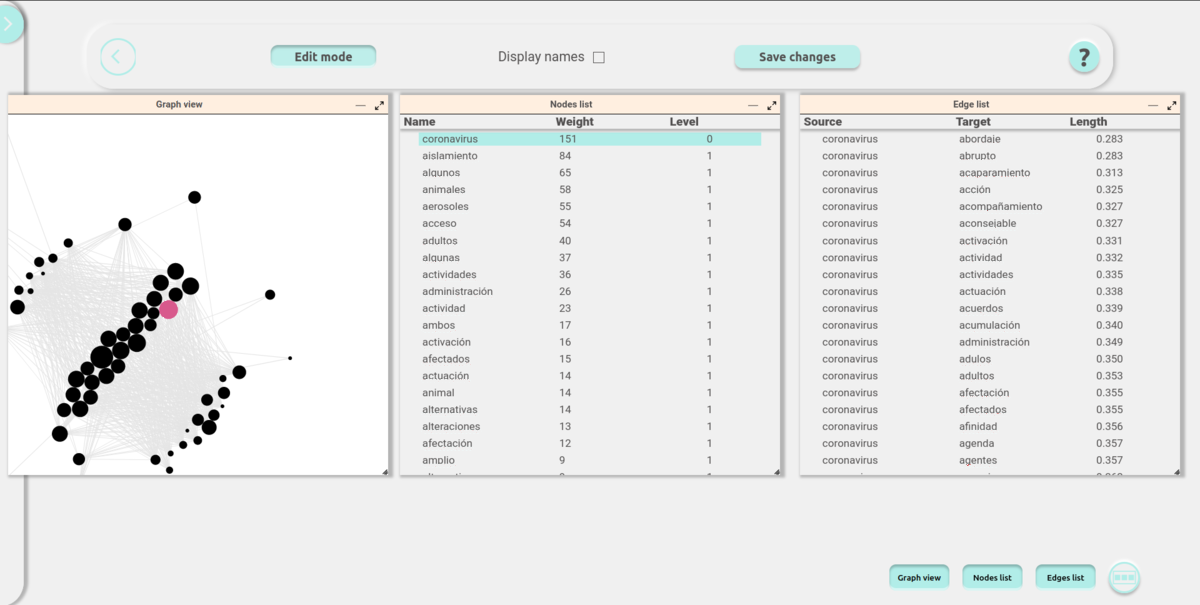
The project had two phases: to develop a robust tool for NLP tasks, and to create two distinct interfaces for interacting with the software. The first interface is a Command-Line Interface (CLI), offering precise control and the ability to automate workflows, targeting to more technically inclined users. The second interface is a web-based platform that communicates with the backend via a Flask API, providing a more user-friendly experience. The web interface also includes interactive visualizations created with D3JS, which allow users to engage directly with the generated graphs and modify them as needed.
The technology stack for DataWave includes a rich array of Python libraries and tools such as Flask for web development, Keras, NLTK, SpaCy, TensorFlow, Gensim, Transformers, and PyTorch for machine learning and NLP tasks. In order to store and manage the huge data volume, the backend relies on MongoDB for database management, while the frontend was developed using SCSS, TypeScript, JavaScript, and D3JS for dynamic graph visualizations.
This project started as my undergraduate thesis (TFG) and continue as my graduate (TFM) thesis, with the project being owned by the department where I conducted my research. The department intends to use DataWave for ongoing research and potentially publish further findings. The project culminated in a publication of a poster, with the results and methodology documented available under the DOI: 10.1145/3656650.3656734 .
One of the most challenging aspects of the project was ensuring that the NLP models could effectively process and extract meaningful data from a wide range of unstructured text sources, including websites, social media platforms like Twitter, and PDFs. This required overcoming significant obstacles related to the variability of data formats and the lack of standardized patterns in the text.